
Most people hear "train an LLM" and imagine a room full of GPUs, a massive dataset, and a budget that only big AI labs can afford.
That version exists, but it is not what most builders need.
If you are building a support assistant, a JSON extractor, a domain-specific chatbot, a code helper, or an internal AI workflow, you probably do not need to train a model from scratch.
You need to take an existing model and make it better at one specific job.
That is the real opportunity with small LLMs.
The goal is not to build the next frontier model. The goal is to build a focused model that is cheaper, faster, more private, and reliable enough for your product.
And the way to do that is not by throwing money at GPUs. It is by narrowing the problem, building a clean dataset, using LoRA or QLoRA, and evaluating the model like an engineer.
First, What Does "Training an LLM" Actually Mean?
When people say they want to train an LLM, they usually mix together a few different things.
Pretraining means creating a base model from huge amounts of text. This is the expensive part. It requires massive compute, huge datasets, and serious infrastructure. Most teams should not start here.
Fine-tuning means taking an existing model and adapting it for a specific task, style, format, or domain. This is what most developers actually mean when they say they want to "train" a model.
RAG means giving the model external knowledge at runtime. Instead of changing the model's weights, you retrieve relevant documents and put them into the prompt.
Context engineering means designing the information flow around the model, so it sees the right instructions, tools, memory, documents, and examples at the right time.
For most products, the decision is not "Should I train an LLM from scratch?"
The better question is:
Do I need to change the model's behavior, or do I just need to give it better context?
That question can save you a lot of money.
When Should You Fine-Tune?
Fine-tuning is useful when the task is stable and repeated.
For example, if you always need the model to return a strict JSON object, classify customer messages, rewrite text in a specific brand voice, extract fields from messy data, or follow the same workflow again and again, fine-tuning can help.
It is especially useful when prompting works, but only with a huge prompt, too many examples, or inconsistent results.
But fine-tuning is not the answer to everything.
If your model is missing fresh company knowledge, use RAG. If the prompt is unclear, fix the prompt. If your workflow is badly designed, fix the system around the model. If you do not have good examples of correct outputs, you are not ready to fine-tune yet.
A simple rule:
Do not fine-tune because the model feels bad. Fine-tune because the behavior you want is clear, repeated, and measurable.
Start With a Small Model
A common mistake is starting too big.
People jump straight to 7B, 14B, or 70B models because they assume bigger means better. Sometimes it does. But bigger also means more memory, slower training, higher serving cost, and more complexity.
If you are doing your first fine-tuning experiment, start small.
A 1B to 4B model is often enough to test the idea. Small models are easier to train, easier to deploy, and easier to iterate on. You can run more experiments, compare results faster, and learn what actually improves performance.
Good model families to explore include Qwen, Gemma, Llama, and Phi.
Do not choose a model only because it is trending on X. Choose it based on your task.
Ask:
- Can I use it commercially?
- Does it support my language?
- Is the context length enough?
- Can I deploy it where I want?
- Does it work well with common fine-tuning tools?
- Is the inference cost acceptable?
The best model is not always the smartest model. It is the model that solves your problem within your budget.
The Dataset Matters More Than The GPU
Fine-tuning is mostly a data problem.
A clean dataset of 500 examples can be more valuable than 10,000 messy examples. The model is not learning your intentions. It is learning patterns from the examples you give it.
If the examples are inconsistent, the model becomes inconsistent. If the outputs are badly formatted, the model learns bad formatting. If your labels are vague, the model learns confusion.
For a first experiment, you can start with 100 to 300 examples. For a serious first version, aim for 500 to 2,000 high-quality examples.
Each example should have a clear input and a clear expected output.
For example, imagine you are training a model to convert messy customer messages into clean support tickets.
Input:
Hey, I paid for pro but my dashboard still says free. Can someone fix this?
Output:
{
"category": "billing",
"urgency": "medium",
"summary": "User paid for Pro but account still shows Free",
"needs_human": true
}This is the kind of task where a small fine-tuned model can be useful. The job is narrow. The output format is clear. The result is easy to evaluate.
Your dataset should include normal cases, edge cases, confusing cases, and examples where the model should refuse or escalate instead of guessing.
And most importantly, keep a test set separate.
Do not train on everything. Hold back examples the model has never seen. That is how you know if it actually learned the task or just memorized your data.
Build a Baseline Before Training
Before you fine-tune anything, test the simplest version first.
Try a better prompt. Try few-shot examples. Try RAG. Try a larger API model. Try the small model without fine-tuning.
This gives you a baseline.
Without a baseline, you will not know if fine-tuning helped. You might spend money training a model that performs only slightly better than a good prompt. Or worse, you might train a model that feels better in demos but fails on real examples.
The baseline keeps you honest.
For a support-ticket model, your baseline might measure:
- How often is the JSON valid?
- How often is the category correct?
- How often is urgency wrong?
- How often does it hallucinate information?
- How often does it correctly ask for human help?
Once you have these numbers, fine-tuning becomes an engineering experiment instead of a vibe check.
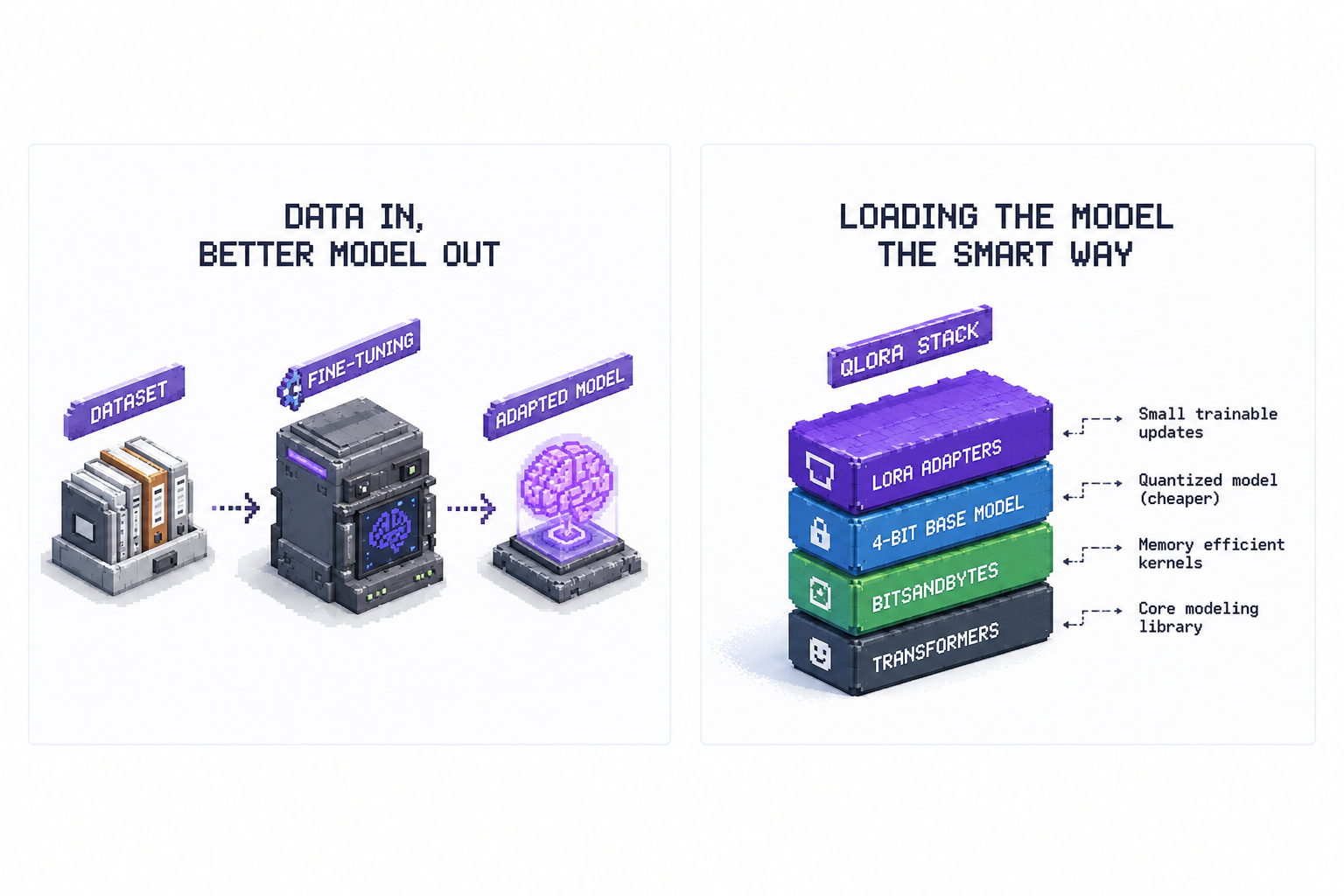
Use LoRA or QLoRA
Full fine-tuning updates all the model weights. That can be expensive.
LoRA is a cheaper approach. Instead of updating the whole model, it freezes most of the original model and trains small adapter layers. You are not rebuilding the entire brain. You are teaching it a new pattern through a lightweight add-on.
QLoRA goes one step further. It loads the base model in a compressed format, often 4-bit, and trains adapters on top of that. This makes fine-tuning possible on much smaller hardware than traditional full fine-tuning.
A simple way to think about it:
- Full fine-tuning is renovating the whole building.
- LoRA is adding a new control panel.
- QLoRA is adding that control panel while storing the building blueprint in a compressed format.
For most indie builders and small teams, LoRA or QLoRA is the practical path.
You can train faster, use less memory, and keep experiments cheap. You can also save adapters separately, compare multiple versions, and avoid duplicating the full model every time you experiment.
The Practical Training Stack
A common stack looks like this:
- Hugging Face Transformers for loading models.
- PEFT for LoRA and QLoRA adapters.
- TRL's
SFTTrainerfor supervised fine-tuning. - bitsandbytes for quantization.
- Unsloth or Axolotl for faster training workflows.
- Weights & Biases, TensorBoard, or even simple logs for tracking experiments.
You do not need a fancy setup on day one.
Your first goal is to make the training loop work with a small dataset and a small model. Then you improve from there.
Keep the first run boring:
- Use a small model.
- Use a small dataset.
- Use a short sequence length.
- Train for a small number of epochs.
- Save checkpoints.
- Evaluate after every experiment.
- Change one thing at a time.
Most money gets wasted when people increase everything at once: bigger model, more data, longer context, more epochs, more tools, more complexity.
Do the opposite.
Start small enough that you can afford to be wrong.
Hyperparameters That Actually Matter
You do not need to become a research scientist to fine-tune a small model, but you should understand the knobs you are turning.
Sequence length matters because longer examples use more memory. If your task only needs short inputs, do not train with a huge context window.
Batch size matters because it affects memory. If your GPU cannot handle a large batch, use gradient accumulation.
Learning rate matters because too high can damage the model's behavior, while too low may not adapt enough.
Epochs matter because more training is not always better. A small model can overfit quickly, especially on a small dataset.
LoRA rank matters because it controls how much capacity the adapter has. Higher rank can learn more, but it can also overfit and cost more.
The best advice is simple:
Start with defaults that already work for your model family. Then change one variable at a time.
Do not blindly copy someone's config from a random notebook and assume it fits your use case.
Evaluate Like an Engineer
This is where many fine-tuning projects fail.
People train a model, ask it a few questions, like the answers, and call it a success.
That is not evaluation.
If your model returns structured output, test JSON validity, schema correctness, required fields, and label accuracy.
If your model is a support assistant, test policy accuracy, escalation behavior, tone, hallucinations, and user satisfaction.
If your model writes code, run the code. Check whether tests pass. Check whether it compiles. Check whether it solves the task.
If your model is part of a product, measure latency, cost per request, memory usage, failure rate, and how often users correct the output.
A good evaluation set should include easy examples, hard examples, edge cases, and examples that look similar but require different answers.
If your eval is "this answer looks good," you are not training. You are guessing.
The Hidden Cost Is Deployment
Training is not the end.
After fine-tuning, you still need to serve the model.
A model can be cheap to train and expensive to run. That matters if your product gets real users.
Before shipping, ask:
- How much memory does the model need?
- What is the latency per request?
- How many users can it handle?
- Can I quantize it for inference?
- Should I merge the adapter or keep it separate?
- Can I run it locally, or do I need a hosted GPU?
- What happens when the model fails?
For local or lightweight deployment, tools like Ollama and llama.cpp can be useful. For more serious serving, teams often look at inference servers like vLLM.
The point is not just to train a good model. The point is to train a model you can actually afford to run.
Common Ways People Waste Money
Most fine-tuning waste comes from avoidable mistakes:
- Training before fixing the prompt.
- Using too much low-quality data.
- Choosing a model that is too large.
- Mixing five different tasks into one small fine-tune.
- Not keeping a test set.
- Training for too many epochs.
- Evaluating on examples from the training data.
- Using fine-tuning to add knowledge that should live in RAG.
- Ignoring inference cost.
- Shipping without monitoring real failures.
The expensive part is not always the training run.
Sometimes the expensive part is building the wrong system around the wrong model for the wrong reason.
A Simple Project I Would Start With
If I were starting today, I would not fine-tune a general chatbot.
I would pick a narrow workflow.
For example:
Train a small LLM to turn messy customer messages into clean support tickets.
The model receives a user message and returns:
- Category
- Urgency
- Summary
- Whether a human is needed
- Suggested next action
The plan would be:
- Collect 300 realistic examples.
- Write a strict JSON schema.
- Test a prompt-only baseline.
- Fine-tune a small 3B or 4B model with QLoRA.
- Evaluate JSON validity and category accuracy.
- Compare latency and cost against the baseline.
- Deploy only if the fine-tuned model clearly wins.
This is a good first project because the task is narrow, the output is measurable, and the value is obvious.
That is the kind of fine-tuning project that makes sense.
Not "let's make our own ChatGPT."
More like:
Let's make a small model that does this one job extremely well.
Final Takeaway
Training a small LLM without burning money is not about finding one magic trick.
It is about making good engineering decisions.
Pick a narrow task. Start with a small model. Build a clean dataset. Create a baseline. Use LoRA or QLoRA. Evaluate before and after training. Think about deployment before you ship.
The future is not only bigger models.
There will be a lot of value in small, focused models that are trained for specific workflows and run cheaply inside real products.
You do not need to beat the biggest model in the world.
You just need to beat your baseline.
Originally shared on X.