
Everyone is talking about loops right now.
Design the system that prompts the agent instead of prompting it yourself. That shift is real and useful. But there is a deeper question that does not get asked enough:
What actually runs the loop when things go wrong?
A simple while true loop in a terminal or a long-running process works fine for short experiments. It falls apart the moment you want the loop to survive restarts, crashes, deploys, or run on a real schedule without losing state.
That is when you realize loop engineering is not just about prompting better. It is also an infrastructure and durability problem.
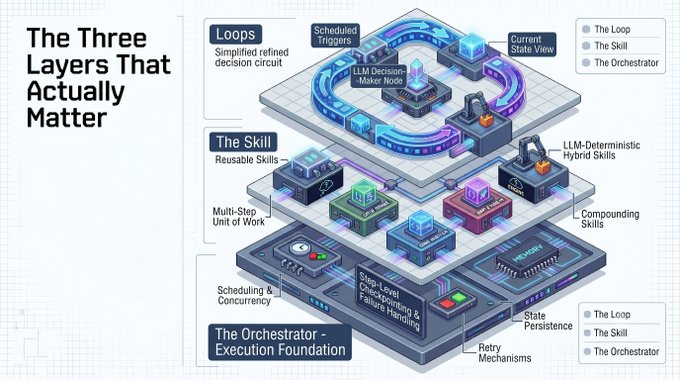
The Three Layers That Actually Matter
If you want loops to work beyond demos, you need to think in three layers.
1. The Loop
This is the decision layer. It wakes up on a schedule or trigger, looks at the current state, and decides what to do next.
The LLM lives inside the loop as the decision-maker, not as the entire system.
2. The Skill
This is the actual unit of work.
A skill is reusable, multi-step, and retryable. It can contain LLM calls, deterministic code, or both.
Skills are what compound over time. Once you build reliable skills, like repo triage, dependency updates, or incident analysis, your loops become significantly more powerful.
3. The Orchestrator
This is the execution layer underneath everything.
It handles scheduling, step-level checkpointing, retries, failure handling, concurrency, and observability. When a process restarts, a good orchestrator knows exactly where it left off instead of starting from scratch.
Right now, most people are only focused on Layer 1. The painful problems - duplicate work, wasted tokens, lost state, and zero visibility - usually come from weak Layer 3.
Why Durability Actually Matters
If your loop dies in the middle of a task, what happens next?
Without proper orchestration, it usually restarts from the beginning. It re-processes data it already handled. It makes the same LLM calls again. It might create duplicate PRs or send the same notification multiple times.
You end up with wasted spend and messy outcomes.
Durable orchestration changes this. Every step gets checkpointed. On restart, the loop resumes from the last successful step.
This is not just about correctness. It also saves money because you stop repeating expensive work.
For anyone running loops on schedules or letting them run for longer periods, this layer becomes important very quickly.
How I Am Thinking About Using This
As someone who works on open-source projects and builds agentic systems on the side, here is how I am approaching this practically.
I am not trying to build fully autonomous systems immediately.
I am starting with narrow, repetitive tasks that already take up my time: keeping repos healthy, handling small maintenance work, or doing initial triage on issues.
For each loop, I define a clear goal and what "done" actually looks like. I keep a simple state file, usually STATE.md, that the loop can read and update. This acts as external memory.
Then I add verification early - usually tests or a second agent checking against project conventions.
I run everything in observation mode first. Only after the loop proves it behaves well on real work do I give it permission to make changes. This has saved me from several expensive or messy mistakes already.
If I am using tools like LangGraph or MCP-style setups, I treat the loop as the orchestration layer on top. The graph handles state and tool execution, while the loop decides when to spawn agents and what goal to give them.
Common Failure Modes
Most loops that become painful fail for similar reasons:
- Weak or missing verification, so the loop keeps going even when the output is low quality.
- Vague goals with no clear stopping condition.
- No checkpointing, so every restart causes the loop to redo work from the beginning.
- Almost zero visibility into what actually happened when something went wrong at 3am.
In most cases, the solution is not better prompting. It is better structure around the loop.
Final Thoughts
The current conversation around loops is mostly about designing better decision flows.
The next layer of progress will come from treating durability, checkpointing, and observability as first-class concerns.
If you are already working with agents on real projects or maintaining open-source work, this is worth paying attention to now. Start with one small, well-scoped loop. Add durability as the importance of that loop increases.
The models will keep changing.
Well-designed loops and durable skills are what actually persist and compound over time.
Originally shared on X.